
























Serverless applications and Docker has been the buzzword for the last couple of years. A few years back there were only one primary option in terms of deploying a production application that one had which has spinning up an EC2 instance and running their server behind an nginx / a load balancer to manage the traffic to each one of their application servers.
Then came Docker. Docker completely changed the way we all look at deployment. 
This never ending problem of environment specific bugs finally started to wash away, because the primary use case that Docker solved was this:

Post docker you don’t need to worry about something working on your machine but not in the production environment. It would be the exact same machine with the exact same configuration that would be running in all the different environments. Your code is always built once, and then that same image is pushed through different environments with no further changes to it. This gave SREs/Devops Engineers as well as developers immense confidence while building an application.
Along with the advent of Docker there was another amazing tech which also gained immense popularity: Serverless applications. Serverless applications also known as FaaS (Function as a Service) is one of those pay as you go service where you don’t need to worry at all about the cost or scalability of your application. Serverless architecture gives you a platform to run a specific piece of code and once it is done with the execution, it destroys itself without you needing to worry about the money that it’s churning even though it’s sitting ducks. This gave developers the flexibility to write highly scalable services without worrying about horizontal scaling.
Code deployment pipeline
Now that we have these cool technologies like Docker it was super easy to spin up as many environments as you want without any need to worry about setting up everything manually. All you need is docker installed on that system and you can get started with docker run.
Hence people started coming up with multiple environment for their applications. People would often come up with a dev, staging, qa, production where at each stages different people in the organisation would test the application and approve it to move forward.
For example:
dev– Is generally used by the developers internally. They would push new code changes very frequently and test it out on a remote server amongst themselves.staging– Once the developers are happy with the bugs that they can sell as features, they would move things to staging. Where probably the product managers can crib about the button colours.qa– Once the product managers are happy with the colours they approve it and move it to qa environment, where the QA team tests the features in the most unusual ways that one can think of.production– Finally if the qa approves that everything has been battle tested the new code is moved out to production environment for the real users to use.
Now different companies would come up with different kind of deployment pipelines based on how their organisation is structured. If the team is very lean and there is no qa team then probably people can just skip that stage.
This pipeline gives a huge certainty that whatever is going out to the final stage has been properly battle tested. Now this deployment pipeline along with Docker gives double assurance because you always know that the same image is being propagated through this pipeline and it would replicate the exact same environment in all the different stages.
Why not serverless with Docker?
Now that we understand how docker along with a deployment pipeline can give us so much of assurance, the question comes why not do something similar for serverless applications as well? Well, this question came up in our internal tech chats few months back 😉
There is this amazing tool serverless, which helps you to deploy serverless applications by just running a couple of commands. It would bundle your codebase and deploy your serverless application to any of the cloud FaaS provider like Google Cloud Function, AWS Lambda or Azure Functions. You even have a way to integrate CI/CD pipeline to deploy your code as soon as you push to a specific branch. But wouldn’t it be great to see the same pipeline mechanism to approve changes at different stages? Well of-course it would and there is already a way to do it, which is branch based deployment. Where you push code to a specific branch and that branch would deploy it to that stage. While this works, it gives rise to a lot of problems:
- You always need to keep track of how the pipeline flows in the branches. So if you have 4 stages then you should always be having those 4 branches in your version control system. And you need to manually make sure that always the correct branch is merged on top the right branch otherwise there will be a jump in the pipeline.
- One can directly push to any branch if they have access. This would result in inconsistent codes in the stages.
- Branch based deployments can always come up with new merge conflicts. It would be the job of the person merging the branch to make sure that there are no conflicts.
- It won’t be super straight forward for someone who is not well versed with version control system. In case of pipelines even the product manager can just come in, click a button and it should magically work but here one has to know how version control system works.
- The more the stages, the more number of branches. Soon it might become an entangled mess if not maintained closely.
How docker helps
As we already talked about how Docker always ensures that the same code is being pushed through different stages, we can probably do something to merge both of these together to gain the flexibility of serverless applications and the same amount of confidence while deploying it through different stages.
The idea here is that with Docker we should be able to bundle the code once and move the same code through different stages. For this we’ll do the following:
- Use a base image of docker which has serverless installed on it.
- Copy the code which needs to be deployed in a docker image and save it.
- Use the same image for deploying it to different stages.
Setting up: serverless with Docker
Base image
We are going to use the above base image in order to deploy our lambda. In order to use this base image in any one of your Dockerfile you can do the following:
- Add the above Dockerfile to a Github repository
- Go to https://hub.docker.com
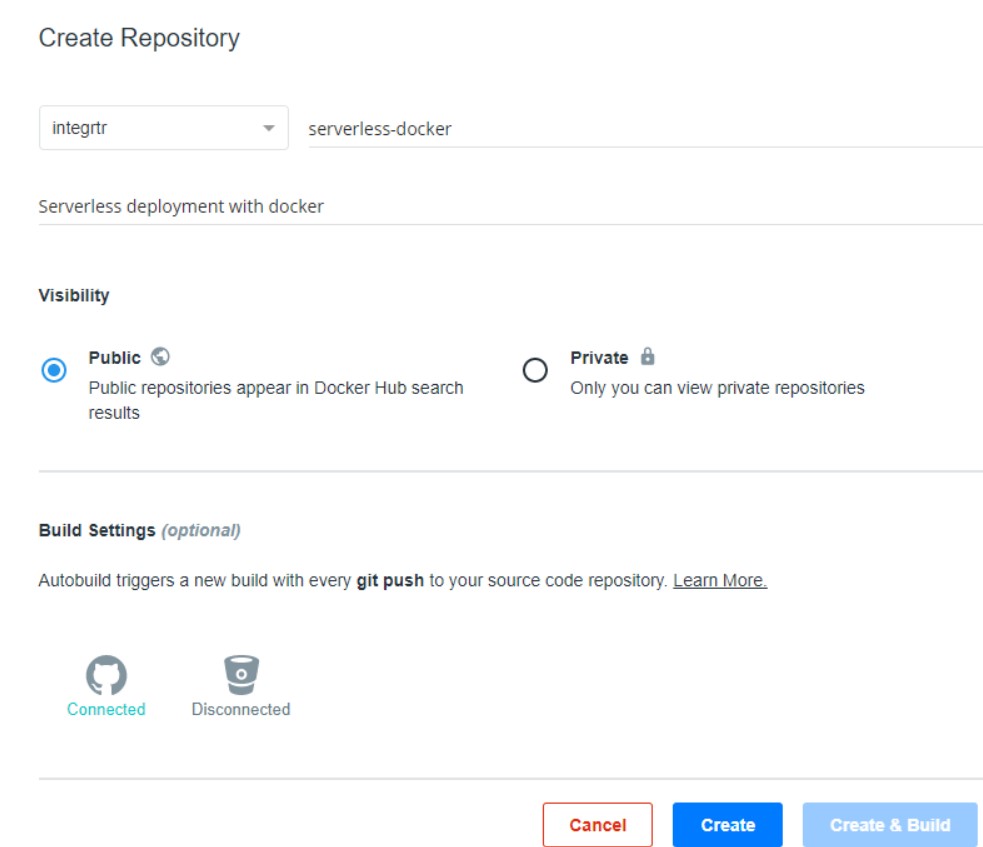
- Create a new Repository:
- Add in the relevant details and keep it public to make things simple
- Select the repository where you have pushed your base image.
- Click on create and build
This should build your base image and host it on docker hub so that you can uses it on any of your application.
Using your username and repository name you should be able to pull this in any of your Dockerfile.
Dockerfile for your lambda
Dockerfile is all you need in order to have your application bundled. This should copy your codebase and install all the dependencies. Once the image is built you can put this in any docker image repository like AWS Elastic Container Service, Docker Hub, GCP Container Registry based on which cloud infrastructure you are on.
Promoting images through stages
In order to promote it through through different stages, this has to be be deployed to an environment without altering or touching the code. For that we will have to pass in a few environment variables to it:
The AWS_SECRET_ACCESS_KEY and AWS_ACCESS_KEY_ID is used to give access rights to the docker container in order to be able to deploy it. STAGE variable helps the serverless configuration to namespace the function appropriately. So that if you are deploying multiple stages you can differentiate them on the cloud function listing page just by looking at the name.
You can get a hang of how you should configure the serverless.yml file from here.
Now in order to deploy the application all you got to do is:
Once you replace the variables with the appropriate values your application should be deployed. For deploying to other cloud providers like GCP or Azure, you’ll probably need provider specific environment variables in order to establish the IAM Role Authorisation.
Maintaining the integrity of the pipe
Now the question comes if one can directly deploy to any of the stage then how do we make sure that they are propagated in the exact same order as that of the original design? Well, in order to maintain that you will have to design a pipeline flow through Jenkins / any other CI/CD platform in order to restrict the promotion of the image. Configuring that is going to be another story in itself which we will talk about in another blog soon.
Conclusion
While this may seem all fascinating but one should never over-engineer their deployment / codebase. If your current setup works well in a small team then there might be no need to setup a complex devops pipeline which might need some learning in itself. Every team will have their own needs and requirements and one should just not use these tech to be the cool kid on the block.
The above architecture and setup works wonders for us because it helps us to:
- Keep a very high level watch on the entire pipeline by just logging into our Jenkins Dashboard.
- Being a lean team it was a one time setup for us which helped us to have immense control over what is going to which stage and review and promote properly.
- Being a completely remove and asynchronous team, even a product manager / a non techie in our team can go ahead and promote things to production without any intervention from someone else by just the click of a button.






